Hello!
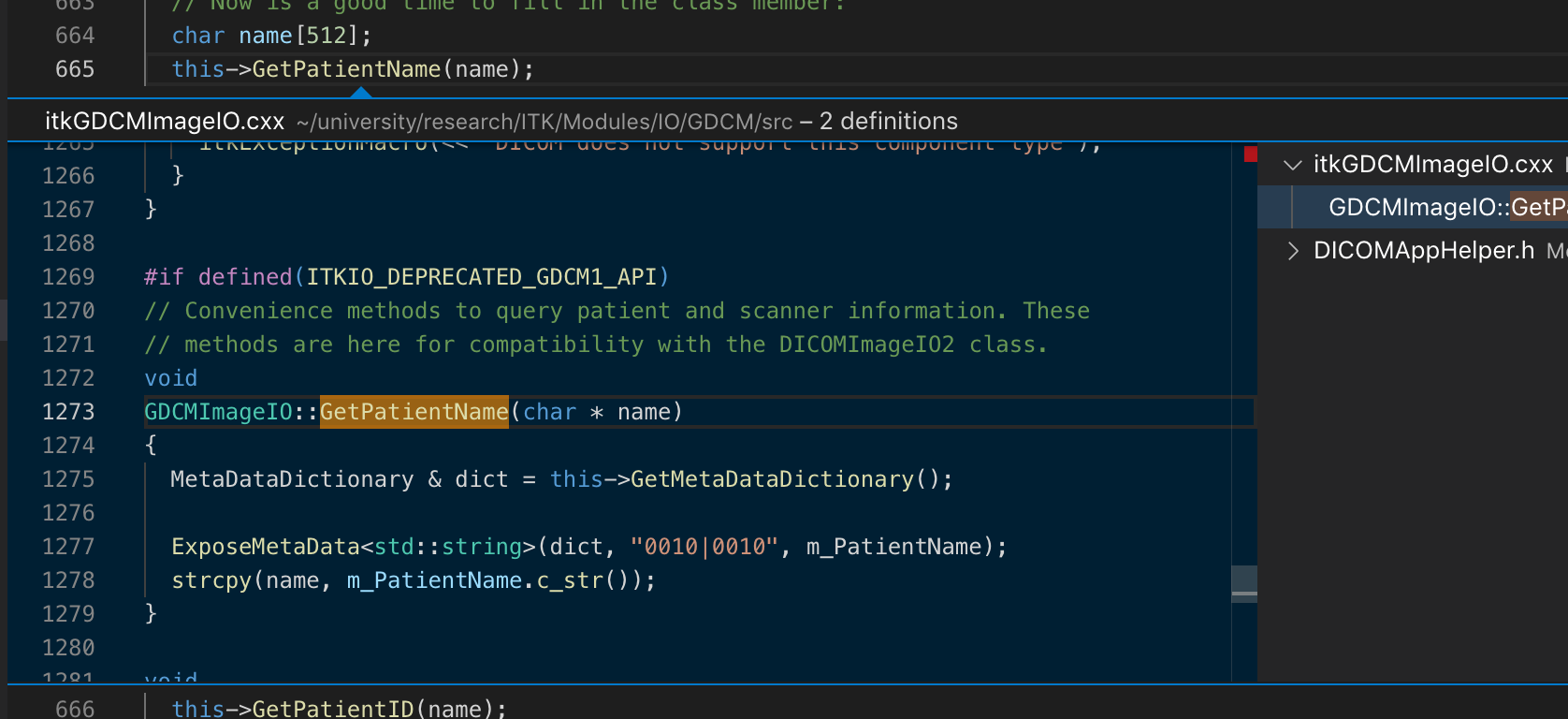
During an internal security assessment of the medical ML pipeline based on Simple-itk we found buffer-overflow in DicomReader.
I guess that it happens because you use the buffer which is located on the stack for getting properties.
In the attached file you can find the file which triggers the buffer-overflow(With long PatientName, the length more than 512) and the source code which we used.
We also tried to read this file with python module The behavior was the same.
buffer_overflow.zip (270.5 KB) .
Thanks.