@zivy thanks so much for your helpful responses on the github thread. Pasting that below for reference
Always use ImageSeriesReader_GetGDCMSeriesFileNames as it returns the list of files sorted along the z direction so that the series reader can create the volume correctly. The series reader just receives a list of images, looks at the distance between the first two along the z direction and assumes that this is the spacing in z for all images.
In a generic setup reading DICOM isn’t trivial as volume slices can reside in different directories or more commonly you have files from multiple series (volumes and other non volume images) in the same directory.
To get a good handle on DICOM reading, please skim the following:
Script that deals with a general directory structure, relevant functions are inspect_single_series and inspect_series.
I completely understand the need for reading images based on spatial coordinates. I am dealing with a large amount of diverse data so I am precomputing the slice order using z-position (and/or x, y position) based on the type of data.
Does ImageSeriesReader_GetGDCMSeriesFileNames always assume data is axial, i,e. using the z position for sort?
In addition to sorting, are there any other benefits that GetGDCMSeriesFileNames provies?
Multiple benefits to using the GetGDCMSeriesFileNames:
You can specify the series ID, so multiple series in the same directory are easily dealt with. The common combination is to call sitk.ImageSeriesReader_GetGDCMSeriesIDs with an input directory, then select the relevant series and call sitk.ImageSeriesReader_GetGDCMSeriesFileNames.
The sorting based on CosinesValues information is a really nice feature. I just did a simple test however, and it seems like ImageSeriesReader_GetGDCMSeriesFileNames is sorting by filename as a default? Is there a way to turn on positional sorting?
dicom_names = reader.GetGDCMSeriesFileNames(path) # list is sorted by name
reader.SetFileNames(dicom_names)
image = reader.Execute()
sitk.WriteImage(image, "/Data/test.nii")
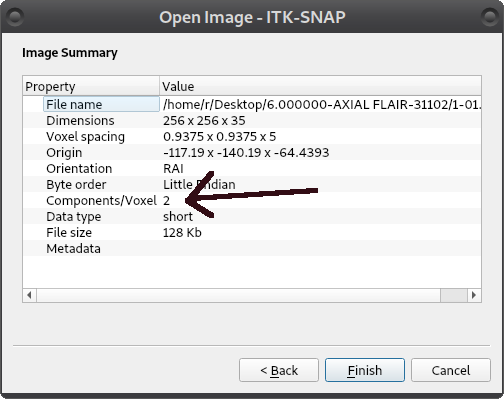
The test.nii file does not correctly sort this middle image correctly. I confirmed this data loads correctly in ITK-Snap and ImageJ.
It is not possible to build uniform volume from that series. 1-01.dcm and 1-02.dcm has identical position/orientation, 1-03.dcm and 1-04.dcm too and so on. Tag 0x0020, 0x1002 “Images in Acquisition” also has value 35, but there are 70 files, instance UIDs are unique. Either it was a mistake during de-identification or intent (3D+t ?). Looks like mistake, but i can not know exactly. I have downloaded that subject (TCGA-06-0185) from TCIA. Seem that in sub-folders
Edit:
Series sorter returns false if slices coincide, s. here, so sorting by file name is fallback. Instance number ordering is also not possible with the series, BTW.
Edit:
i manually split into 2 series 35 images each and i think it was a mistake, probably during de-identification, both have absolutely identical pixel values, so hard to imagine it were 3D + something.
That’s really interesting @mihail.isakov. So the sample I was using to test had duplicated data which must be a mistake in TCIA – thanks for pointing that out!
Interestingly ITK-Snap handles this well. It automatically loads 35 images ignoring the duplicate and sorting by position. So it guess it only allows one image per Image Position (0020,0032)?
To implement this using sitk, I could filter images to make sure there is only per Image Position, which should then allow GetGDCMSeriesFileNames to sort using spatial location. Does that plan make sense to you?
Not sure, there are also DWI and perfusion series in the study, they are 4D.
BTW, DWI series might have another issue, i don’t see b-values, diffusion direction, neither in standard tags nor in private tags, may be they were deleted together with private tags. Do you need DWI from that subject?
Just wanted to follow up with a more specific question. Do you have a suggestion for handling Diffusion and Perfusion data with an additional component? Are there a few dicom tags that are generally reliable for this?
In particular case seems to be possible to remove erroneous duplicates looking at Instance Number (0x0020,0x0013) in series. It is not required and even bad idea for general purpose reader, it could be used only to repair series from 3 affected folders of that subject. Reliable is, of course, SOP Instance UID (0x0008,0x0018), if it is unique - an image is unique, but in particular case probably the mistake happened before ‘anonymizer’ was used and ‘anonymizer’ generated instance UIDs (?). Luckily such problem is very rare, can not happen with original DICOM data.
Edit: @Akshay_Goel , may be just skip these 3 folders (listed somewhere above), if you don’t need them. Or repair (semi)-manually once and don’t include this logic in your reader.
Thank for that feedback. I am trying to create something that can handle issues with deleted fields that arise from anonymization.
I have to figure out a fallback for Perfusion and Diffusion cases. I will take a look at Instance Number. If this is missing perhaps there is a way to ascertain the grouping from other attributes. This is a small edge case so not a major priority but if you have thoughts let me know!