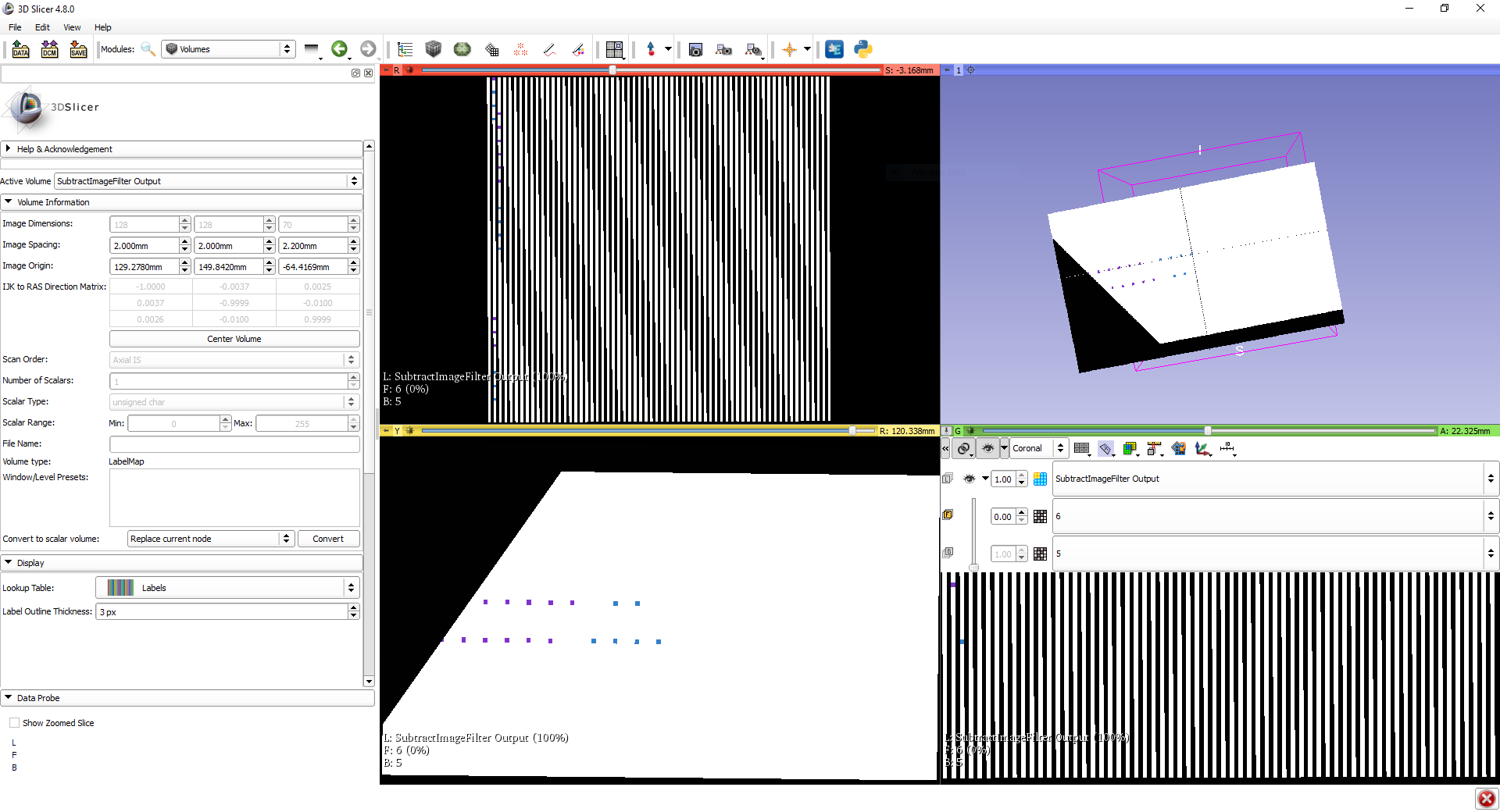
Here is a somewhat simple test case that fails for me on visual studio 2015 builds. You can see from the slicer screen grab the patterned differences where interpolator results are different by (typically) 1.
If I come up with a better test case I’ll add it here. The one from the actual code is a bit more complicated and also larger difference, this is the simplest trigger I’ve come up with so far. The geometry numbers come from that example though and seem to be significant.
Also, I hope to have a proper look at why this is happening this week, but can’t for a couple of days. So if anyone has ideas or similar experiences, I’d love to hear them. I’m also not very familiar with that codebase so it may be slow going.
Do you have a measure of the magnitude of the per pixel error?
The algorithm used for “linear transforms” is done in an optimized scan line basis:
This methods just compute the “delta” in the scanline direction and accumulates it as it move along the scanline. This would result is subtle numeric differences than if the full transform from the fixed to the moving was done.
Now if a different “ImageRegionsSplitter” was used the results could be slightly different becausethe default way to split the images (currently) should ensure that the fast scan line is never split.
However in the problem that caused this, i was using NearestNeighbor, not linear. Unfortunately I haven’t found as simple a test case that generates it with NN. I will try to autogen an image that trips that up too if it helps. Or perhaps find one I can share.
In the NN case I would expect direction to be irrelevant, no?
The direction matters for which pixels get interpolated, and interpolation matters for coming up with values. So image direction does affect nearest neighbor interpolation.
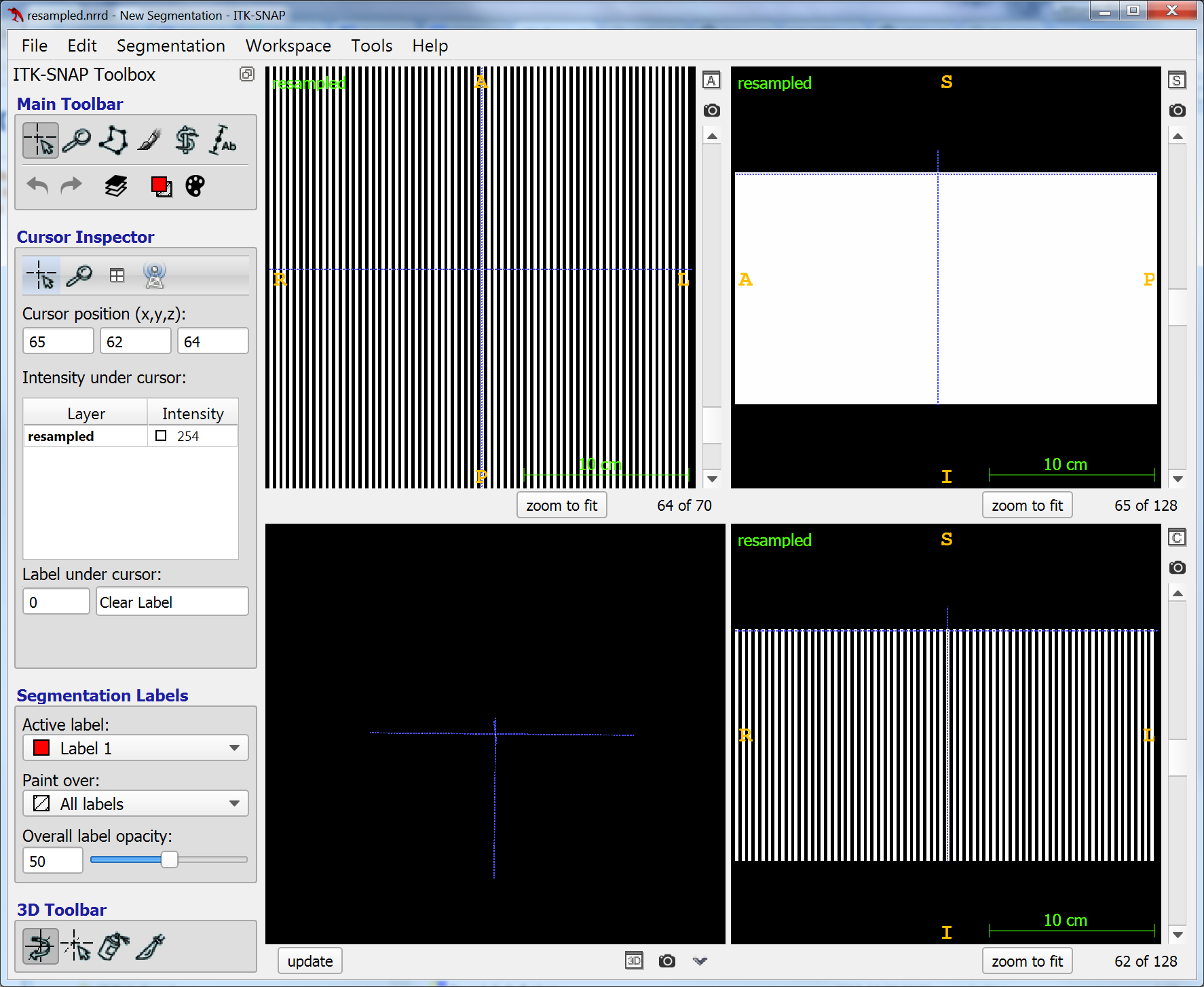
I tried the example, and I have consistently been getting this kind of image: stripes with value 254 and 253. I didn’t notice whether this is thread-dependent. I used ITK-4.12.0-vs2017.
Sorry, I should have been more careful with my choice of words. Clearly the image direction matrix matters in choosing which pixels are interpolated. However, while accumulation order could change the linear result a little bit, I can’s see how the choices of ImageRegionsSplitter could affect a nearest neighbors result. Am I missing something?
What is the numeric cause of the difference?
The resampling is does from continuous physical space to continuous physical space, so it is done with double precision. With the limitation of finite bits, the computations for coordinates to sample from is imprecise which will require some interpolation. The pixel type is of “unsigned char” the result of the interpolator is then implicitly rounded via truncation. So a slight difference in location can result in 254 vs 255. Consider using “float” for the output pixel type followed by the “RoundImageFilter”
Why is it different with thread numbers?
This is tougher as I suggested I could see a different Region Splitter could the cause. Could you be using a different one? The other is some funny SSE instructions making the scan line dependent on each other. OR other bad optimization done.
My intuition is the numerics are not problematic, but will keep in mind.
I’m not convinced my simple test captures enough of it, I’ll try and construct a more representative one. Once I have that I can try with all optimizations off to see if it’s optimizer related.
The Splitter could most definitely have an effect even with NearestNeighbor interpolator. If the result of the accumulation is .499999 vs .500000001 you could land on a different pixel.
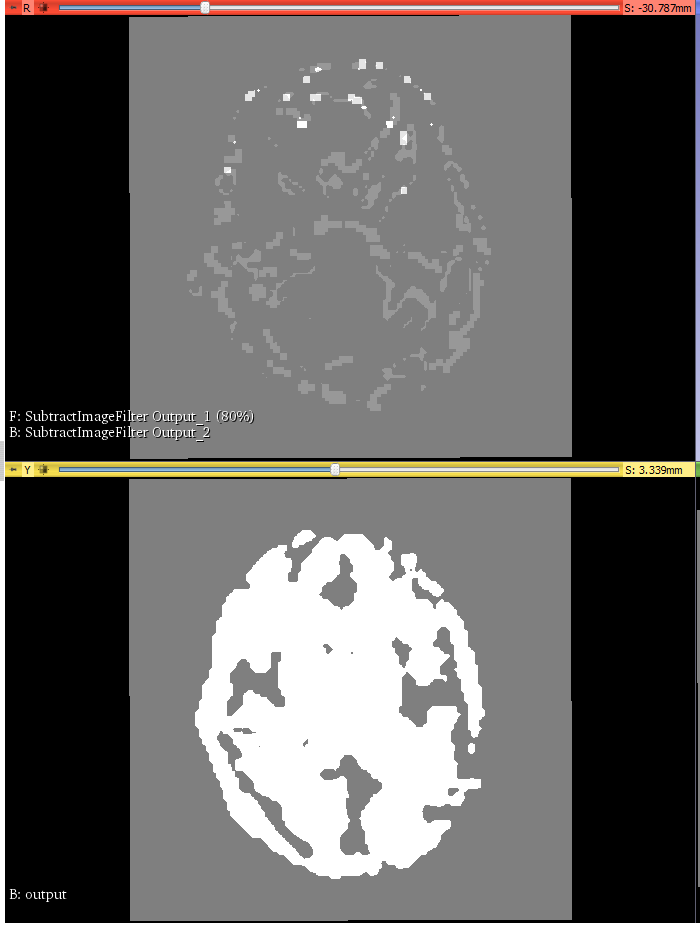
Unsurprisingly, the accumulation version doesn’t match recomputing position at every point. Attached snapshot shows difference between reference (position recomputed always) and 1 and 8 thread resamplers using the acumulation menthod (i.e. code in 4.13).
bottom is reference image, top is the deltas between reference and 1-thread (bright) 8-thread (dim). You can see how feeding this mask through additional morphological operations can result in quite different outputs for different threads. I should point out that the screenshot is centered on one of the slices that have differences, of course much of the volume is identical.
The key issue here I think is the delta, as computed it is {0.99999999999999756, 6.9111383282915995e-15, 3.5527136788005009e-15} }
My preferred method for resampling masks has be to create a 0-level set from the mask via a distance field filter. Then resample the distance field. This approach is free from many aliasing issue, and more numerically stable with the usage of a linear or higher order interpolator.
@blowekamp : true, I use that approach in other places, and this is an oversimplified test. However this isn’t about aliasing in the result - I was surprised by the different behaviour based on thread count. This will affect any resampling of similar geometry, of course, just be more difficult to see. In the particular case I have I can make it more stable, but I’m still looking to avoid regressions between machines with different core counts…
Fundamentally this isn’t a big impact but I’m not sure the speed tradeoff is always worth the non-determinism of the scanline approach. Any correction factors for the accumulation errors, etc. are probably going to get close to cost of recomputing the position each time.
For what it’s worth, I’ve already resolved the original regression a different way.