Hello, I do work with non-human head CT and MRI. My goal is to allow users to load nifti images into my program to be segmented and output in stl format for 3d printing. I’m pulling a lot of code from Dave Chen’s dicom2stl.
I’m running into troubles with handling inconsistencies with FOV and orientation between subjects. For example, some images are full body supine scans while others are just of the head in the sphinx position. I’ve tried DICOMOrientImageFilter with mixed results, such that 2 images I try to orient “LPS” will come out differently. Also the metadata are not always correctly labeled for these orientations.
My goal is to minimize user input, but realize we may need to take some fiducials from the user. My intuition is to crop and register to an atlas image, but I’m not entirely sure.
Possibly try a slightly more computationally expensive and robust registration initialization strategy? Relevant SimpleITK notebooks registration initialization and a specific use case. The problem with wrong meta-data in the DICOM is not uncommon, see discussion in the registration initialization notebook.
Hi @zivy,
Thank you! I’m wondering as far as good practices though, is it okay to be registering/initializing a larger full-body FOV scan (moving image) onto a smaller average scan of just the head? Or should I save cropping until after I’ve registered?
Swapping between smaller and larger image roles is problematic. The registration transformation maps points from the fixed_image to the moving_image. If the fixed_image is physically larger, many of the points will be mapped outside the smaller moving_image and we won’t be able to compute the similarity.
The common initialization approach, align the centers of the volumes, assumes both images cover about the same sized object and then this approach makes sense.
In your case aligning the small volume with the center of the large volume is not appropriate. You would potentially divide the large volume into sub regions and check the similarity metric value if your initial transformation mapped the center of the atlas to the center of the region (not center of volume). Think template matching.
Thanks again @zivy
For simplicity sake, is taking user input to crop the image to be relatively the same size as the atlas a fair approach before initializing? I plan to use the gui.ROIDataAquisition() from the notebooks for this purpose.
If so, it seems there are a number of approaches. Should I just slice the image to the ROI? Use ExtractImageFilter()? CropImageFilter()? I’m having trouble understanding the difference from the documentation.
Cropping to approximately the same size as atlas is a fair initialization.
Extract image filter is usually used to reduce dimension, e.g. extract a 2D slice from a 3D image. You could use Crop, but I think it would be easier to control RegionOfInterest filter.
Your question is related to a broader one, user+algorithm or algorithm. Things to think about:
Is one minute of user interaction preferable to x minutes of compute time? Does the user need to wait for the computation to complete. Does user interaction provide robustness that the automation lacks? How complex is the user interaction?
Generally speaking, when designing a workflow the user+algorithm should complement each other.
Note that the ROI approach only reduces the search space, if the objects in the images are 180 degrees rotated, registration will still fail even if the translation is “known via cropping”. So if this happens with the data you will still need to explore the parameter space.
A possibly simpler approach to cropping is to have the user identify a single corresponding point in both images, align the fixed image to the moving image (larger one) using this point and then, no need for cropping. Still need to explore parameter space due to rotation.
@zivy
Alright, cropping seems to be successful, but the registration seemed off. As a test, I loaded the atlas image in a different orientation using DICOMOrient(), and tried to use the code from 63_Registration_Initialization to register onto itself with little success (points do not match up when viewed using the RegistrationPointDataAcquisition() gui). I kept all parameters the same from that notebook.
Based on your description it is hard to guess what went wrong. How far is the initialization from the final transformation? That notebook uses a rigid transformation for registration. You are using an atlas, so rigid is not appropriate, affine is more appropriate.
Before going any further, I’d recommend that you do a “manual registration”. The portion titled Register using manual initialization in the notebook. Modify the transformation type to affine, the rest remains the same. See if affine does a reasonable job, if yes, then once you’ve done the cropping just run an affine registration without trying the robust initialization portions of the notebook (the manual registration only served for evaluating whether affine works).
The multires_registration is angostic to the type of transformation. Settings should work for all global transformations, not ideal but will work. The settings will not work for BSpline or DisplacementField.
and comment out the lines converting from a Versor to Euler that appear afterwards. Finally, with affine we require a minimum of four corresponding 3D points (with rigid the minimum is three).
@zivy
Okay the manual registration from the atlas onto itself is much better with this change.
I notice that running the MetricEvaluate cell for initialization actually doesn’t return a best orientation value other than (0,0,0) regardless of what I feed to the DICOMOrientImageFilter() when I first load the image (e.g. RIA, LPS, RPI, etc). Here’s an example of 2 orientations of the same atlas image that give no transformation for best orientation.
per the DICOMOrientImageFilter() documentation, “The physical location of all pixels in the image remains the same”. I get the feeling I shouldn’t be using this to test the sampling of parameter space, perhaps better to do an actual transformation beforehand?
I added an orientation in the initialization code that nearly matches your transformation (np.pi/2.2), hoping that the initial transform would get the registration close, then the multires function would do the rest. However, the multires function seems to be worse! Pasted below are corresponding points from the initial and final transforms (initialization and multires respectively). Notice the final transform is accurate in x and y, but is 10 slices off in Z.
When initializing the affine transformation, are you only using 4 points? If so, are they on the same plane? This is a degenerate configuration, so likely registration will fail if initialized in this manner. If only using 4 points, try to space them as far from each other as possible, results will be more stable with respect to errors in the point localization.
Hi @zivy ,
I am using just 4 points, and tried again following your suggestion of far apart points. Performance increased marginally (3-4 slices in z error rather than 9-12). I wonder what my expectation should be here? Especially with manual initialization I thought the registration onto itself should be near perfect, is this not true?
Also the optimizer’s stopping condition is the default from 63_Registration_Initialization:
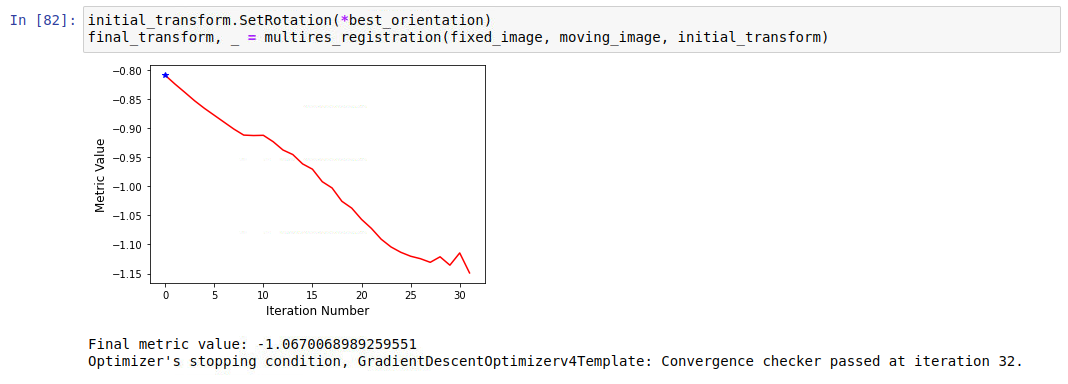
“Optimizer’s stopping condition, GradientDescentOptimizerv4Template: Convergence checker passed at iteration 9.”
Number of iterations is very low, indicates something is not going well with the registration. You can try the following, comment out the code sections associated with multi-scale settings of the registration (SetShrinkFactorsPerLevel, SetSmoothingSigmasPerLevel, SmoothingSigmasAreSpecifiedInPhysicalUnitsOn) and run at full scale. See if the similarity measure is really going down.
I expect the registration to converge, but really depends on the initialization. Can you plot the progress of the similarity metric during the process and post that here so that we have a better idea of what is going on?
So, doesn’t look too great in terms of how it is converging, number of iterations is small. Two things to try: first, increase the sampling percentage from 0.01 to 0.1. If that doesn’t help, reduce the learningRate to 0.1.