I have a directory containing files with .dcm.dcma extension.
It contains 4 series.
I can easily open it with ITK-SNAP or Slicer3D.
I run sitk.ImageSeriesReader_GetGDCMSeriesIDs on it and it simply freezes without returning anything.
I can’t get no error message whatsoever to help debug this.
@Roulbac I guess this is hard to reproduce if the community is not given further information. If you think this is a bug, please consider opening an issue. Read the instructions in the appropriate issue template.
Since this looks specific to your data, providing your data will hopefully
Help people debug the issue and hopefully come up with useful comments, and eventually a solution.
Broaden the testing data pool of ITK so that regressions are added on your data, the toolkit becomes more robust, and the issue is never reproduced.
Here’s an update;
I ran it on a more powerful computer with Ubuntu 16.04.5
Same problem.
If i wait a little longer, i get thrown this error
RuntimeError: Exception thrown in SimpleITK ImageSeriesReader_GetGDCMSeriesIDs: std::bad_alloc
Please let me correct myself on this.
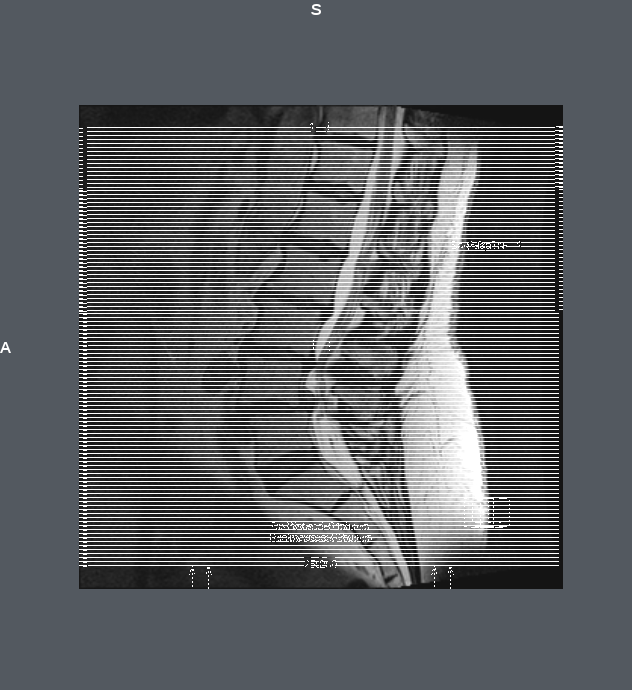
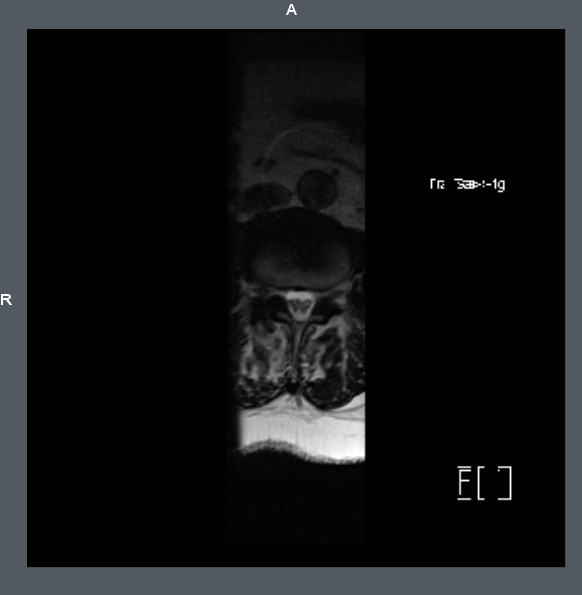
This hangs on Slicer only for one series among all, that’s the AXIAL_MPR series. I am able to read IDs, names, metadata and all for all series, but when trying to load the image, AXIAL_MPR causes ITK-SNAP and Slicer to hang.
Same for ITK-SNAP; I’m able to load all series besides that one.
In my use case I need to extract all readable series from the DICOM;
so if a series like the AXIAL_MPR one causes me trouble I should just discard it; whereas here with SimpleITK I cannot even read all other series in my DICOM folder because it detects that the AXIAL_MPR series cannot be read so it just throws an exception for the entire DICOM folder.
Using ITK-SNAP 3.8.0 and Slicer 4.8.1 on High Sierra
Update:
This is the error in the Slicer logs when I try to load that series
Warning in DICOM plugin Scalar Volume when examining loadable 100: AXIAL MPR: Images are not equally spaced (a difference of 11.5 vs 1 in spacings was detected). If loaded image appears distorted, enable ‘Acquisition geometry regularization’ in Application settins / DICOM / DICOMScalarVolumePlugin. Please use caution.
Tried to patch it with the Slicer Dicom Patcher, got this error:
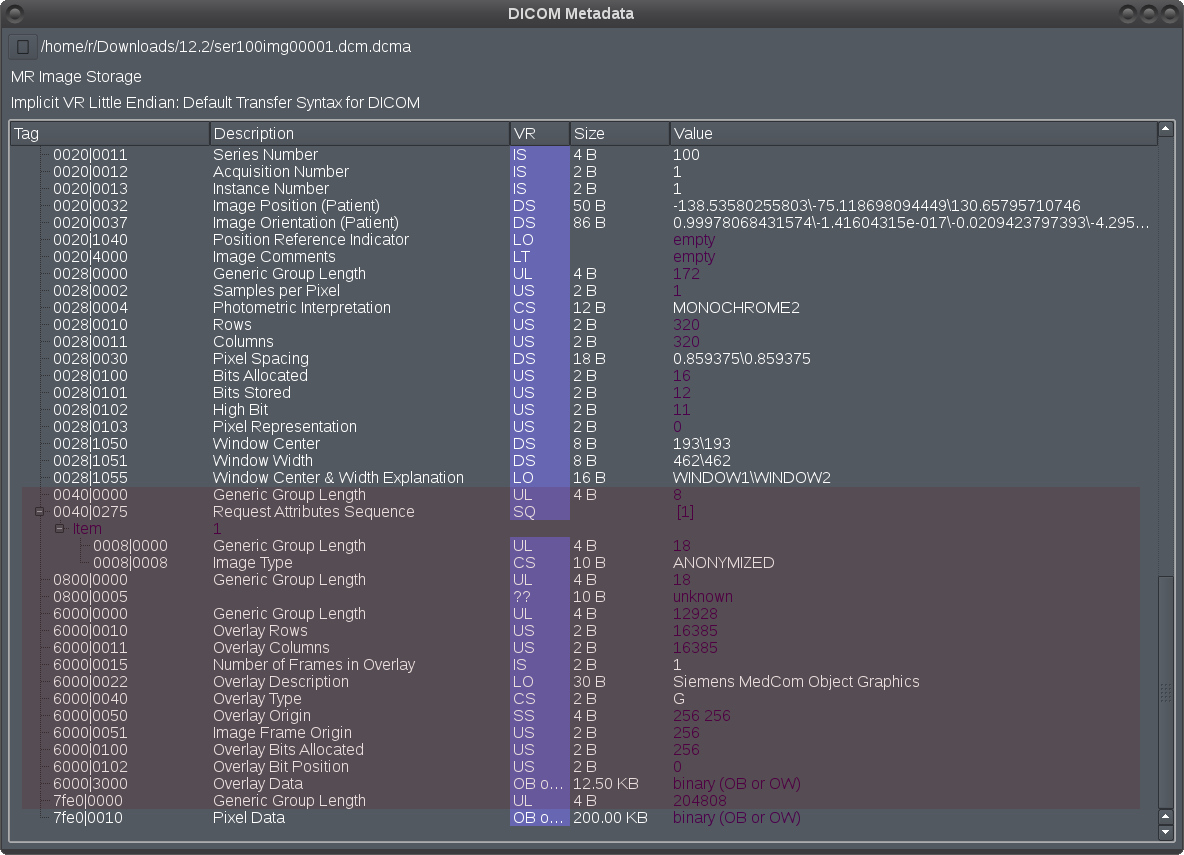
Unexpected error: Invalid tag (0800, 0005): "Unknown DICOM tag (0800, 0005) - can’t look up VR
Also had the same error trying to open it with pydicom
I guess somebody tried to add overlays and messed files, may be. Overlays are removed, they were unsable: with rows, colums 16385 and bits allocated 256, may be i shall try to recover overlays too (they are AFAIK not processed in software you use).
Thank you very much for your help!
This is just one sample though, I have many DICOMs like these. These are from a public research dataset and it is big.
Do you mind sharing your solution or tell me how you repaired the dicom and what’s the procedure to follow?
Edit: I have no need for overlays I am only interested in the volumes.
Still working on this so far, help is much appreciated
Apart from wrong overlays problem - there is evil file ser100img00251.dcm.dcma
1st it is 484x484 but belongs to series with 251 files, other are 320x320, so it invalidates volume. And it has some data problem, hanged or crashed every viewer i tried, not sure. I have remove everything from (0040,0000) to pixel data (7fe0,0010) - this file only. From other files removed overlays.
Say i go through every file in the directory, read metadata and group files together with same uid (0020|000d) and size then pass each group to imageseriesfilereader; does that sound reasonable to you?
Also, how do I remove overlays?
Not sure, real problem was some data size problem in ser100img00251.dcm.dcma. Overlays are very wrong but most software don’t try to load. About different dimension in series it is hard to predict what is correct. Probably no reason to do anything, if you get problems with other series we can look at.
import shutil
import os
import argparse
import gdcm
def get_series_dict(dirpath):
directory = gdcm.Directory()
loaded = directory.Load(dirpath)
assert loaded
print('Loaded dir')
scanner = gdcm.Scanner()
seruid_tag = gdcm.Tag(0x0020, 0x000e)
scanner.AddTag(seruid_tag)
scanned = scanner.Scan(directory.GetFilenames())
assert scanned
print('Scanned dir')
uids = scanner.GetValues()
series_dict = {}
for uid in uids:
series_dict[uid] = scanner.GetAllFilenamesFromTagToValue(
seruid_tag, uid)
return series_dict
# Go through each serie, get largest filename group with consistent size
# Assuming rows = cols at all times
def get_largest_subfnames(fnames):
fname_grps = []
s = gdcm.Scanner()
row_tag = gdcm.Tag(0x0028, 0x0010)
s.AddTag(row_tag)
s.Scan(fnames)
vals = s.GetValues()
for val in vals:
fname_grp = s.GetAllFilenamesFromTagToValue(row_tag, val)
fname_grps.append(fname_grp)
return max(fname_grps, key=lambda x: len(x))
def remove_overlays_grouplens(f):
ds = f.GetDataSet()
it = ds.GetDES().begin()
tags_to_rm = []
while not it.equal(ds.GetDES().end()):
de = it.next()
t = de.GetTag()
if (0x601e >= t.GetGroup() >= 0x6000
and t.GetGroup() % 2 == 0):
tags_to_rm.append(t)
for t in tags_to_rm:
ds.Remove(t)
an = gdcm.Anonymizer()
an.SetFile(f)
an.RemoveGroupLength()
an.RemoveRetired()
an.RemovePrivateTags()
if __name__ == '__main__':
parser = argparse.ArgumentParser()
parser.add_argument('-i', type=str, required=True,
help='Input directory for repair')
parser.add_argument('-o', type=str, required=True,
help='Directory where to output repaired dcms')
args = parser.parse_args()
output_dir = os.path.abspath(args.o)
if os.path.exists(output_dir):
shutil.rmtree(output_dir)
os.makedirs(output_dir)
series_dict = get_series_dict(args.i)
for sidx, suid in enumerate(series_dict.keys()):
if (len(series_dict[suid]) == 0):
continue
series_dict[suid] = get_largest_subfnames(
series_dict[suid]
)
for fidx, fname in enumerate(series_dict[suid]):
reader = gdcm.Reader()
writer = gdcm.Writer()
reader.SetFileName(fname)
if not reader.Read():
print('Could not read {}'.format(fname))
continue
f = reader.GetFile()
remove_overlays_grouplens(f)
writer.SetFile(f)
out_fname = os.path.join(output_dir, '{}_{}.dcm'.format(sidx, fidx))
writer.SetFileName(out_fname)
if not writer.Write():
print('Could not write {}'.format(name))
This is my solution, I was able to remove the evil slice that’s got a different shape using a gdcmScanner that’s scanning through each series filenames and grouping names by the row tag 0x0028, 0x0010, I used GDCM’s anonymizier class to remove grouplengths.
Although having reproduced your solution, I am still not able to read the volume with 250 slices.
Is there any extra step that you took that allowed you to read the 250slice volume?
Hello,
Not sure, but i could reproduce, may be this approach will work
Move 484 x 484 file (ser100img00251.dcm.dcma) away from the folder
For the rest of files in 250 series remove everything between (0028,1055) and pixel data (7fe0,0010). There are some broken tags and broken overlays, nothing important.
After that i could load series, also in Slicer.
Step 1 I was able to reproduce, removing the img00251,
Step two, do you mean that I should remove all tags with hex codes between those two, meaning 0028,1055 <= hexcode code <= 7fe0,0010 or just remove only those two tags?
 .
.