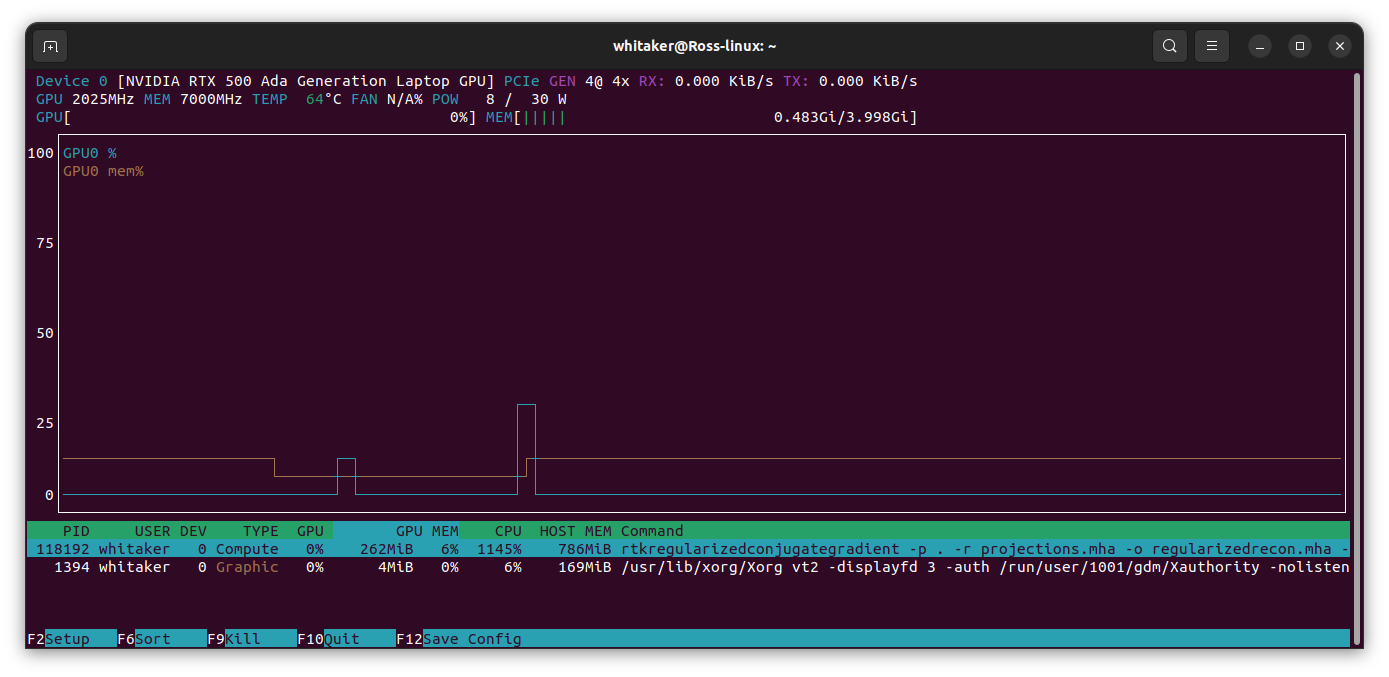
I am using RTK to do iterative reconstruction. Everything seems to be working, except when trying to run things on the GPU. Everything compiles fine and it runs. However, when the GPU-compiled programs run, they are slow, slower than the CPU versions. nvtop shows that the process is present on the GPU, but that it is using 0% of GPU processing while it is hammering the CPU. This is true of RTK code that I wrote as well as the RTK-ready applications such as rtkfdk, admmtv, conjugategradient, etc. I have compiled (clean) ITK with the flags ITK_USE_GPU and RTK_USE_CUDA. Below is a list of system stuff (for reference) and the display from nvtop. Any pointers/advice is appreciated.
Could you please provide a concrete example of what you’re trying to do? For rtkfdk, you need to use the option --hardware cuda. For iterative reconstruction, you need to use forward and backprojectors, e.g. --fp CudaRayCast --bp CudaVoxelBased.
Thanks so much for your help. RTK is really a great resource, and I have been studying how it is put together. Great design and software.
I am still having some trouble getting the GPU to engage consistently. When I run the applications that are built in RTK from the command line. Things work as expected. That is, the application uses the GPU consistently and does not use the CPU much. To determine this I use nvtop in linux. So for the commands:
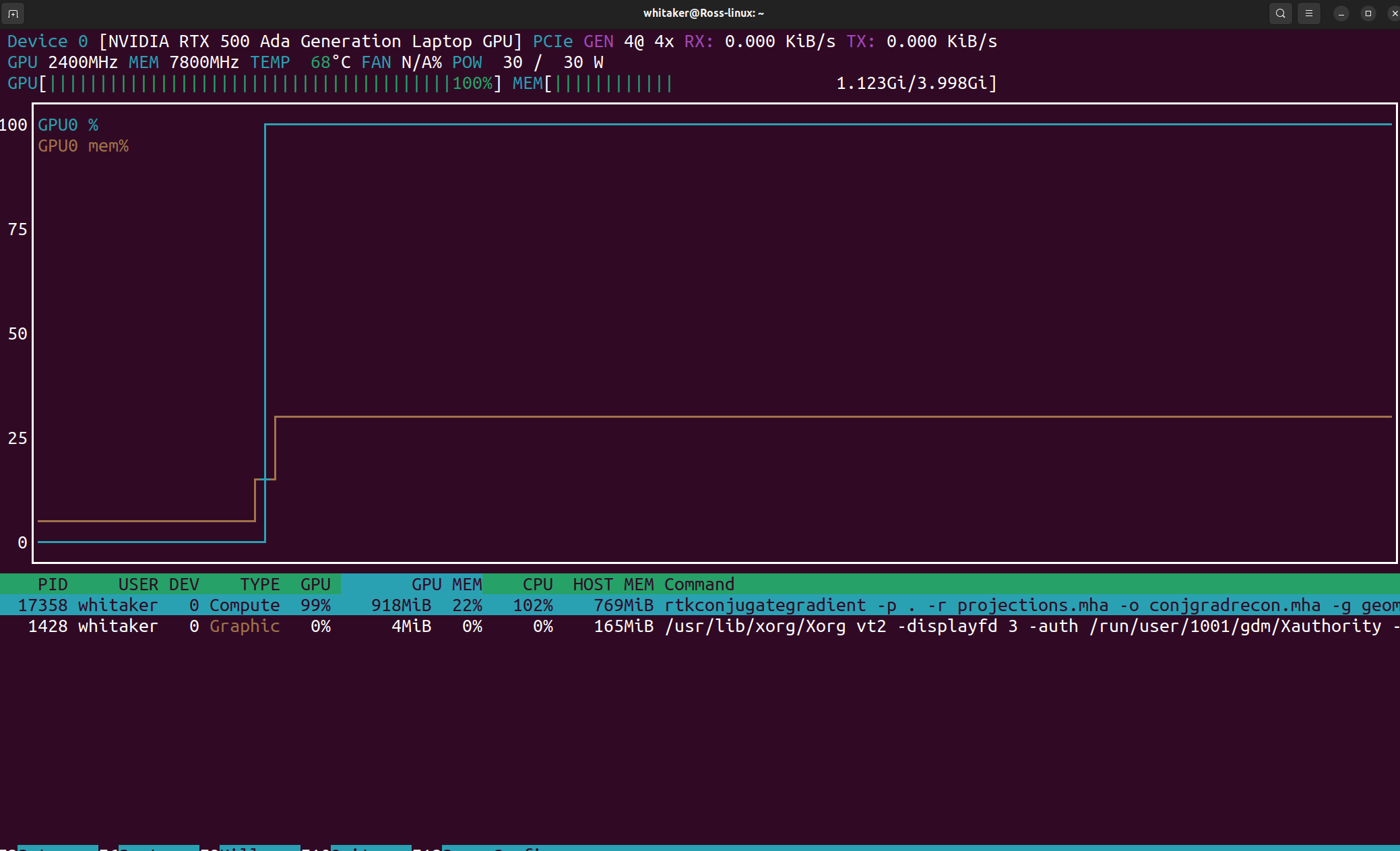
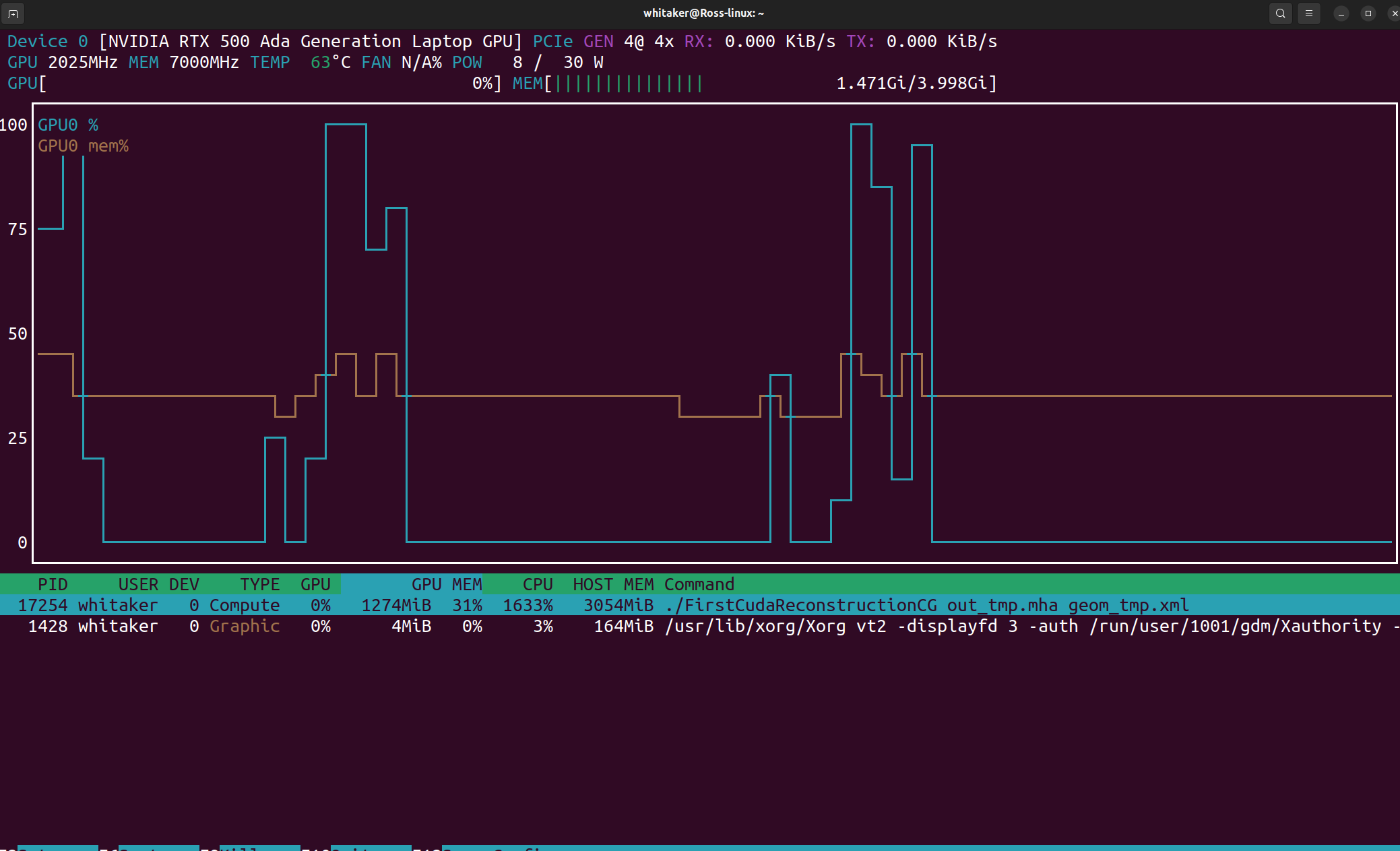
Which makes sense. Everything seems to be computed on the GPU. Very little use of the CPU during the iterative reconstruction process. However, if I create my own CG iterative code (.cxx attached), I get a different behavior, for the same geometry and reconstruction volume. There is a burst of GPU activity at each iteration and then the process hammers the CPU for several seconds. Like this:
I figure that some piece of the processing is not being done on the GPU. Must be some filter that I have not GPU enabled. However, I have not yet been able to figure out what I am missing. I have verified that the projections and the volume for reconstruction are cuda images, and all of the filters are templated for cuda images.
I don’t know what could be the issue, I would have expected the same behaviour. Is your code indeed slower than the command line application?
My suggestion would be to run the two codes with the exact same parameters and to turn on the CMake option RTK_PROBE_EACH_FILTER. The --verbose option of the command line tool will then report the time spent in each filter. You can do the same in your code, see code here, and compare the printed results to understand what filter is causing this.
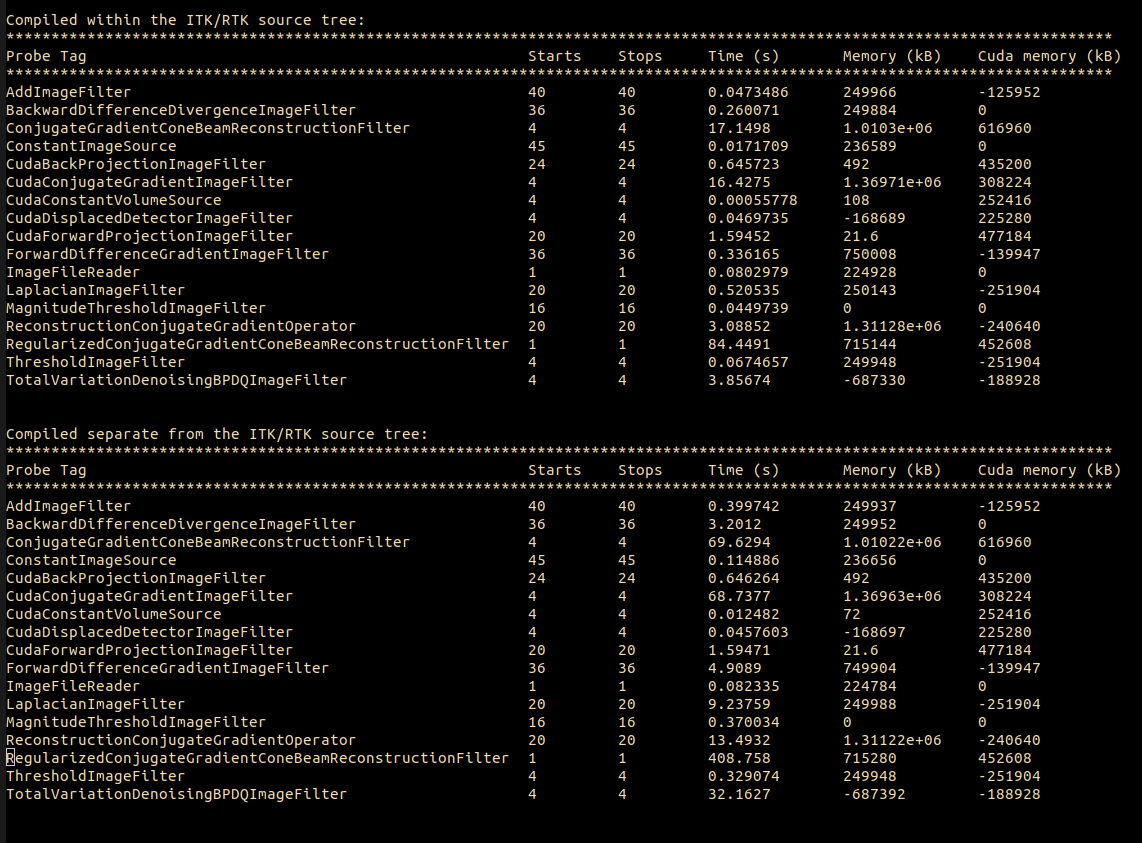
Sorry for the delayed response. I have done some experiments and the probing as you suggested (very cool stuff). I have figured out that the difference between the fast-GPU case and the slow-GPU case. The slow case is compiled outside of the ITK/RTK source/build tree with a separate CMakeLists file (attached). Below are the results of the probe. The slow case takes about 5x as long. There must be some flag or something that I am missing that causes the code compiled outside of the source tree to not run properly. I have confirmed that ITK_USE_GPU and RTK_USE_CUDA are both defined at compile time. Not sure what else to look at.
Thanks again for all your help (and for supporting RTK!).
Thanks for sharing. Most likely, you didn’t set the CMAKE_BUILD_TYPE CMake option to Release? This is important to let the compiler optimize the compilation.