I’m having troubles to reproduce exactly the same results with the N4BiasFieldCorrection in Windows vs. Linux. Even more strange it does work for certain cases, but not for others. I’ve tried already many things and checked previous posts related to multithreading and others, but now I’m running our of ideas. I describe all the details here:
01 : Produces exactly the same results in Windows and Linux
02 : Does not produce exactly the same results in Windows and Linux. After doing the substraction of the two resulting [float] images, the maximum difference is 0.00268555. It sounds negligeable but might have an effect in posterior processing steps.
The machines I’m using to test are:
Windows Machine: 4 Cores, 8 Logical processors. Windows 7
Linux Machine: 48 Cores, 2 Threads per core. Ubuntu 18.04.1 LTS
An example of the command line used to run these tests:
N4BiasFieldCorrectionApp.exe -i inputImage.nii.gz -m mask.nii.gz -o out_linux.nii --num-threads 8
I included the last parameter in my executable because I noticed that the only way to obtain same results in different machines with different cores was to assign the number of threads to a specific value:
When this is not set in the code, the results varies according to the number of cores in the machine, i.e. two machines with different number of cores (e.g. two Windows machines 4 cores and 8 cores) give different results if these options are not added. Usually the differences are in the 3rd or 4th decimal if float images are used.
Setting these options work to reproduce same results for some cases (e.g. the case 01), but strangely not for others (e.g. case 02). Although, the input images and the compiled code are equivalent.
Do you have any idea of what could be inducing a different result in certain cases?
I can try, but we need to understand anyway what is happening with v4. I saw there were some changes in this module for the RC v5 indeed, but not sure how this would affect the fact that works in certain cases and not in others.
Moreover, we are already using v4 in other applications and it’s becoming critical to know how much these discrepancies are inducing an error in the results. This N4BiasFieldCorrection filter is used in many pipelines around the world and just thinking that every machine gives a different result is a bit shocking.
This should not be shocking at all. Floating-point results are often somewhat different depending on what compiler, compiler options, and hardware you use.
You may force high-precision computation, which may make the results more consistent but increases computation time. If an algorithm is robust then these small numerical differences should cause negligible difference in the final output.
I truly and fully agree with you. The algorithms should be robust enough to manage small variations on the values or at least to evaluate how sensitive are the algorithms to those changes. Probably it was a bit too much to mention that it is shocking, but for instance many neuroimaging pipelines use this N4BiasFieldCorrection module and so far I have not seen any evaluation of these variations in posterior steps. When you consider that some of them use registration and/or optimization procedures that work with floating point values, then I think it is important to evaluate this effect on the algorithms.
In our case we do have some posterior steps that seem to be affected by this variation, so running a linux-based Docker image of this code vs running a Windows exe, may produce different results, only in certain cases that we cannot identify a priori.
My next questions are:
Is v5 RC1 improving somehow this consistency? Do you also expect a particular difference vs v4.11.0?
How do we enforce this high-precision computation in CMake?
We are also exploring why our algorithms are so sensitive to these changes, but I think it is also important for the community to know that this may happen.
@rcorredorj For you information, ITK5 (RC1) does include a few major performance improvements of the N4BiasFieldCorrectionImageFilter, from pull requests that I submitted last year:
Compared to ITK4, I observed more than 40% reduction of the run-time duration of an Update() of the filter, with these three improvements. None of them should have any effect on the results (and indeed, I did not observe any changes to the results). But of course, it’s very useful that you’re testing the reproducibility!
I’m starting to test ITK v5 RC01 in the two machines. I will keep you posted.
So far I had a compilation/installation error after launching the INSTALL target in VS2017.
In file Modules\ThirdParty\VNL\src\vxl\vcl\cmake_install.cmake, line 75, the bin folder is wrongly appended to the install prefix for the vcl_compiler_detection.h, as highlighted in red in the following image. After removing this from the cmake_install.cmake file, the installation continued without any issues. Compilation and installation in Linux didn’t need any change, didn’t have any problem.
I had more troubles in Windows and Linux compiling against ITK in the installed directory (the one defined in INSTALL_PREFIX), so I definitely used the BIN folder as suggested in this thread: Neural Networks Examples
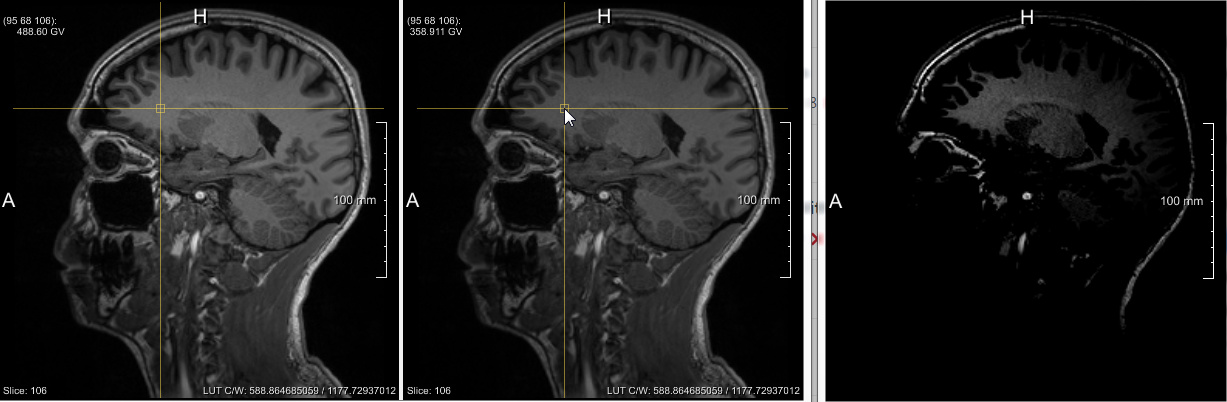
In addition to this, I’m able to reproduce same results in the two machines, Windows and Linux, using v5rc01. This is good news, but I was a bit surprised by the differences between v5rc01 and v4.11.0. The bias seems to be corrected in a different way. The following image shows in v4 in the left, v5 in the center and the difference between both in the right (after playing with contrast level). The differences are between -0.00715885 and 332.423. The cursor is located in a voxel where the differences are higher than 100…
I checked the last changes on the N4BiasFieldCorrection filter and I mostly saw improvements in performance, but then, which could be the reasons of such a change in the results? Overall, we have the impression that the results are better, but we cannot confirm this as we don’t have a validation dataset for this N4 correction.
It is recommended to use the itkShrinkImageFilter before launching the N4BiasFieldCorrection. However, that undersampling does not consider any particular interpolation as far as I saw. Moreover, if I change the original orientation matrix of the image to the identity matrix, I obtain different results when when I do a voxel-wise comparison of the undersampled images.
Is there a particular reason to use that ShrinkImageFilter ? Does it make sense that the results are different when the orientation of the same image is different?