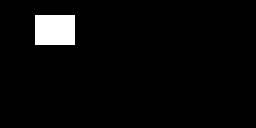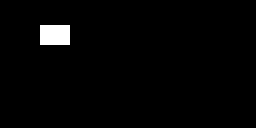Unfortunately this isn’t the same issue. I’m using the simplest registration setup I could (the patch appears to be specific to mutual information which I’m not using).
The current issue is more generic/fundamental to the registration framework - it is not a problem with a specific metric it is a “feature” of the ImageRegistrationMethodv4 (see the link in my original post). The use of the mask in the larger image is expected to limit the sampling so that it isn’t across the whole image, only inside the mask. The use of rejection sampling to do this results in too few samples, so registration fails even when the user is providing enough information for it to succeed. In this example I expected the mask to be equivalent to cropping the fixed image to the ROI.
The SimpleITK code illustrating the issue is below so that you have all of the information (see which optimizer/transform/mask I use + any bugs I have  ) .
) .
import SimpleITK as sitk
import numpy as np
alpha = 0.5
####################################
# Register the two images, starting with the identity transform. The two
# images completely overlap.
####################################
def estimate_translation(fixed_image, moving_image, fixed_mask):
transform = sitk.TranslationTransform(2)
registration_method = sitk.ImageRegistrationMethod()
registration_method.SetMetricAsCorrelation()
registration_method.SetMetricSamplingStrategy(registration_method.RANDOM)
number_samples = 256
percentage = number_samples/ np.prod(fixed_image.GetSize())
registration_method.SetMetricSamplingPercentage(percentage)
registration_method.SetOptimizerAsGradientDescent(learningRate=1.0, numberOfIterations=100, convergenceMinimumValue=1e-6, convergenceWindowSize=10)
registration_method.SetOptimizerScalesFromPhysicalShift()
registration_method.SetInitialTransform(transform, inPlace=True)
registration_method.SetMetricFixedMask(fixed_mask)
final_transform = registration_method.Execute(sitk.Cast(fixed_image, sitk.sitkFloat32),
sitk.Cast(moving_image, sitk.sitkFloat32))
return transform.GetOffset()
####################################
# Create images, fixed and moving and the fixed image mask.
# Image content is a rectangle which is shifted by dx,dy in the moving image.
####################################
def create_images_and_fixed_mask(img_height, img_width, dx, dy):
rect_width = 30
rect_height = 20
rect_start_x = 40
rect_start_y = 20
npa = np.zeros((img_height, img_width))
npa[rect_start_y:rect_start_y+rect_height,rect_start_x:rect_start_x+rect_width] = 255
fixed_image = sitk.GetImageFromArray(npa)
mask_start_y = rect_start_y - 5
mask_end_y = rect_start_y+rect_height + 5
mask_start_x = rect_start_x - 5
mask_end_x = rect_start_x+rect_width + 5
npa[mask_start_y:mask_end_y, mask_start_x:mask_end_x] = 255
fixed_mask = sitk.GetImageFromArray(npa) == 255
npa = np.zeros((img_height, img_width))
npa[rect_start_y+dy:rect_start_y+rect_height+dy,rect_start_x+dx:rect_start_x+rect_width+dx] = 255
moving_image = sitk.GetImageFromArray(npa)
return (fixed_image, moving_image, fixed_mask)
dx = 0
dy = 5
img_height = 64
img_width = 128
fixed_image, moving_image, fixed_mask = create_images_and_fixed_mask(img_height, img_width, dx, dy)
sitk.WriteImage(sitk.Cast(fixed_image,sitk.sitkUInt8), "small_fixed_image.png")
sitk.WriteImage(sitk.Cast(moving_image, sitk.sitkUInt8), "small_moving_image.png")
sitk.WriteImage(sitk.Cast(fixed_mask*255, sitk.sitkUInt8), "small_fixed_image_mask.png")
#sitk.Show((1.0 - alpha)*fixed_image + alpha*moving_image, "small combined image before registration")
errors_x = []
errors_y = []
for i in range(1000):
est_x, est_y = estimate_translation(fixed_image, moving_image, fixed_mask)
errors_x.append(np.abs(est_x - dx))
errors_y.append(np.abs(est_y - dy))
print('small image errors x mean(std), errors y mean(std): {0} ({1}) {2} ({3})'.format(np.mean(errors_x), np.std(errors_x), np.mean(errors_y), np.std(errors_y)))
img_height = 128
img_width = 256
fixed_image, moving_image, fixed_mask = create_images_and_fixed_mask(img_height, img_width, dx, dy)
sitk.WriteImage(sitk.Cast(fixed_image,sitk.sitkUInt8), "large_fixed_image.png")
sitk.WriteImage(sitk.Cast(moving_image,sitk.sitkUInt8), "large_moving_image.png")
sitk.WriteImage(sitk.Cast(fixed_mask*255, sitk.sitkUInt8), "large_fixed_image_mask.png")
#sitk.Show((1.0 - alpha)*fixed_image + alpha*moving_image, "large combined image before registration")
errors_x = []
errors_y = []
for i in range(1000):
est_x, est_y = estimate_translation(fixed_image, moving_image, fixed_mask)
errors_x.append(np.abs(est_x - dx))
errors_y.append(np.abs(est_y - dy))
print('large image errors x mean(std), errors y mean(std): {0} ({1}) {2} ({3})'.format(np.mean(errors_x), np.std(errors_x), np.mean(errors_y), np.std(errors_y)))