i wonder if there are any relationship between the CUDA version of compiling RTK linked and the CUDA version of RTK applying environment,because i met a strange problem that a same procedure runs faster on my pc than that on a better epuiped computer with 2 4090 GPUs, and only the CUDA version is different,i tried to oberve the usage rate of GPU,the usage rate of GPU runs highly during the procedure running,it means the procedure did called GPU .but what is the reason for time cost difference?
I don’t have an answer but I would first check that the bottleneck is indeed the computation and not I/O differences between computers. There is a cmake option in RTK (RTK_PROBE_EACH_FILTER) to know where time is spent, maybe it would help comparing the two.
You might also want to change the CMAKE_CUDA_ARCHITECTURES option to activate compile options suitable for 4090 GPUs, the current default is low to be compatible with most cards.
thank you for replying,firstly,my ITK’s verison is 5.2.1,and RTK’s version is 2.3,i compiled them with cmake-gui,i can not find the keys which named RTK_PROBE_EACH_FILTER and CMAKE_CUDA_ARCHITECTURES ,but i find RTK_PROBE_EACH_FILTER in cmakelist.txt in RTK’s suorce package,and i modify it from off to on,is it means i need compile RTK again and new dlls will help me find out where the time is spent?by the way,how to set CMAKE_CUDA_ARCHITECTURES to activate compile options suitable for 4090 GPUs,i just know the RTX 3080 for value 86,there is no infomation for 4090,
The cmake options are probably in the advanced options.
To display timing information, you need to call rtk::GlobalResourceProbe::GetInstance()->Report(std::cout);.
For architectures, I think 4090 is Ada Lovelace so 89, see CUDA - Wikipedia.
thank you,i got the way to display timing information,but i want to know between rtk::GlobalResourceProbe::GetInstance()->Start(char*) and rtk::GlobalResourceProbe::GetInstance()->Stop(char*), if i need call Update()?now i call Update() in last step which is FOVfilter;
No, all filters that have been compiled after inclusion of rtkMacro.h will automatically record the information. That would be all filters for an executable with rtkMacro.h included first thing. This is based on a redefinition of the New macro:
thank you for replying! i compiled RTK again,i set CMAKE_CUDA_ARCHITECTURES by adding a newline set_property(TARGET RTK PROPERTY CUDA_ARCHITECTURES “86;89”) in RTK/src/cmakelist.txt and i got new dlls,then i test in my procedure,it seems that there is no improvement in speed on better equiped computer,on the other hand,i called `rtk::GlobalResourceProbe::GetInstance()->Report(std::cout) to display timing information,it shows that fdkfilter takes up the vast majority of time,the total time is 76s,and fdkfilter cost 43s.on my computer,total time is 53s,fdkfilter cost 22s,i don’t know why is it and what to do to help it,could you please give me some advice,thanks!
It is useful to look at the details. FDK is a composite filter. What should take most of the time is the ramp filter and the backprojection. Are they both slower on this machine? Don’t hesitate to post the two logs.
i called CudaFDKConeBeamReconstructionFilter on my procedure,how can i figure out What should take most of the time is the ramp filter and the backprojection,replace CudaFDKConeBeamReconstructionFilter with ramp filter and the backprojection?
No, rtk::GlobalResourceProbe::GetInstance()->Report(std::cout); should provide the details, doesn’t it?
if i just call rtk::GlobalResourceProbe::GetInstance()->Report(std::cout) there is nothing show,i used rtk::GlobalResourceProbe::GetInstance()->Start() and rtk::GlobalResourceProbe::GetInstance()->Stop() between filter start and end ,it will show the timing information
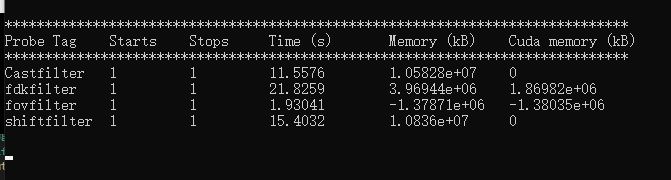
that’s the timing information
It does not look like you have activated RTK_PROBE_EACH_FILTER but that you do the probing manually. If it were activated, you would get something like this (here with rtkfdk):
$ rtkfdk -p . -r his -o test.mha --like fdk.mha -v -g geometry.xml
Regular expression matches 355 file(s)...
Reading...
Reading geometry information from geometry.xml...
Reconstructing and writing...
FDKConeBeamReconstructionFilter 99% completed.
*******************************************************************************************************************
Probe Tag Starts Stops Time (s) Memory (kB) Cuda memory (kB)
*******************************************************************************************************************
ConstantImageSource 1 1 0.00070715 0 0
CropImageFilter 355 355 0.000190987 0.0225352 0
DisplacedDetectorForOffsetFieldOfViewImageFilter 23 23 0.000468327 0 0
ElektaSynergyRawLookupTableImageFilter 355 355 0.000145972 0 0
ExtractImageFilter 23 23 0.000613192 0 0
FDKBackProjectionImageFilter 23 23 0.00418923 0 0
FDKConeBeamReconstructionFilter 1 1 0.741545 12936 0
FDKWeightProjectionFilter 23 23 0.00112339 0 0
FFTRampImageFilter 23 23 0.023475 562.435 0
ImageFileReader 355 355 0.000567063 4.8 0
ImageSeriesReader 355 355 0.000727532 4.8 0
LUTbasedVariableI0RawToAttenuationImageFilter 355 355 0.000922433 0 0
LogImageFilter 355 355 0.000163057 0 0
ParkerShortScanImageFilter 23 23 0.000502255 0 0
ProjectionsReader 1 1 0.889115 445160 0
StreamingImageFilter 2 2 0.79476 183412 0
SubtractImageFilter 710 710 0.000144491 0 0
ThresholdImageFilter 355 355 0.000141167 0 0
Maybe you can check that RTK_PROBE_EACH_FILTER is set and that rtkConfiguration.h is the first include in your main file as in rtkfdk before including `rtkMacro.h’?
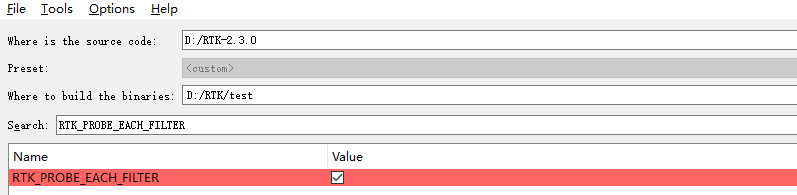
when compiled RTK,i choosed this setting,and i checked the cmakelist.txt,there is a line written "option(RTK_PROBE_EACH_FILTER “Probe each RTK filter in a global object and report times and memory used in RTK applications” ON) ",in my main file, i have include
rtkConfiguration.hbefore including `rtkMacro.h’,but just call rtk::GlobalResourceProbe::GetInstance()->Report(std::cout) shows nothing
Can you check if your rtkConfiguration.h file has indeed the line
#define RTK_PROBE_EACH_FILTER
?
I don’t know what’s wrong otherwise if rtkConfiguration.h and rtkMacro.h are included first (before, e.g., FDK)
rtkConfiguration.h file dosn’t have indeed the line
#define RTK_PROBE_EACH_FILTER
and i add this to it,after rebuilding RTK, i got the detailed information of timing,CudaFDKConeBeamReconstructionFilter takes up the vast majority of time.last but not the least,the main purpose of this topic is to deal with the difference between 2 computers,i want to know how to fix it,theoretically,a better equiped computer runs faster than a bad one.
Indeed, so can you post the two timing outputs for comparison?
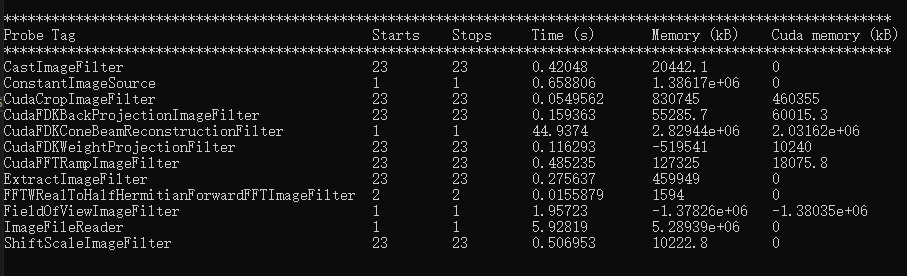
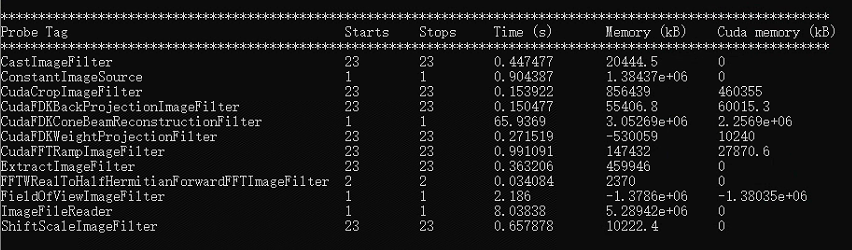
So the backprojection is slightly faster on the 4090 GPU but the ramp filter is two times slower. Interestingly, the CudaCropImageFilter, which does not compute much, is three times slower so it might be a suboptimal use of the memory cache. Maybe increasing RTK_CUDA_PROJECTIONS_SLAB_SIZE to e.g. 32 will help? There is also a number of hard coded constants in RTK (tBlock_x, tBlock_y, tBlock_z) which would benefit from being tuned for each architecture.